Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-06 更新
EDTalk: Efficient Disentanglement for Emotional Talking Head Synthesis
Authors:Shuai Tan, Bin Ji, Mengxiao Bi, Ye Pan
Achieving disentangled control over multiple facial motions and accommodating diverse input modalities greatly enhances the application and entertainment of the talking head generation. This necessitates a deep exploration of the decoupling space for facial features, ensuring that they a) operate independently without mutual interference and b) can be preserved to share with different modal input, both aspects often neglected in existing methods. To address this gap, this paper proposes a novel Efficient Disentanglement framework for Talking head generation (EDTalk). Our framework enables individual manipulation of mouth shape, head pose, and emotional expression, conditioned on video or audio inputs. Specifically, we employ three lightweight modules to decompose the facial dynamics into three distinct latent spaces representing mouth, pose, and expression, respectively. Each space is characterized by a set of learnable bases whose linear combinations define specific motions. To ensure independence and accelerate training, we enforce orthogonality among bases and devise an efficient training strategy to allocate motion responsibilities to each space without relying on external knowledge. The learned bases are then stored in corresponding banks, enabling shared visual priors with audio input. Furthermore, considering the properties of each space, we propose an Audio-to-Motion module for audio-driven talking head synthesis. Experiments are conducted to demonstrate the effectiveness of EDTalk. We recommend watching the project website: https://tanshuai0219.github.io/EDTalk/
PDF 22 pages, 15 figures
Summary
利用视频或音频输入,独立操控嘴巴形状,头部姿态和情绪表情,实现高效可控的面部生成。
Key Takeaways
- 提出 Efficient Disentanglement 框架,实现解耦面部动作。
- 利用三模块分解面部动态,独立操控嘴巴形状,头部姿态和情绪表情。
- 采用可学习基底,通过线性组合定义特定动作。
- 强制基底正交,加速训练,确保动作独立。
- 提出 Audio-to-Motion 模块,实现音频驱动面部生成。
- 实验验证 EDTalk 的有效性。
- 提供项目网站:https://tanshuai0219.github.io/EDTalk/
- 论文标题: EDTalk:高效解耦说话人头部生成框架
- 作者: Tan Shuai, Qiangqiang Yuan, Lu Sheng, Fan Yang, Zhixin Piao, Changjie Fan
- 第一作者单位: 清华大学
- 关键词: 说话人头部生成、解耦、面部动画、音频驱动
- 论文链接: https://arxiv.org/abs/2207.03559
- 摘要: (1) 研究背景: 说话人头部生成需要对多个面部动作进行解耦控制,并适应不同的输入方式,这需要深入探索面部特征的解耦空间,确保它们既能独立操作又可以保留与不同模态输入共享的能力。 (2) 过去方法及问题: 现有方法往往忽视了这些方面,导致解耦空间不独立、训练速度慢或无法处理音频输入。 (3) 研究方法: 提出 EDTalk 框架,采用三个轻量级模块将面部动态分解为三个不同的潜在空间,分别表示嘴型、头部姿态和表情。每个空间都由一组可学习基组成,其线性组合定义了特定的动作。通过正交化基并设计高效的训练策略,确保了独立性和加速了训练。 (4) 任务和性能: 在说话人头部生成任务上,EDTalk 实现了出色的性能,在视频和音频输入条件下均能实现嘴型、头部姿态和表情的独立控制。实验结果验证了 EDTalk 的有效性,证明了其在说话人头部生成中的应用潜力。
方法
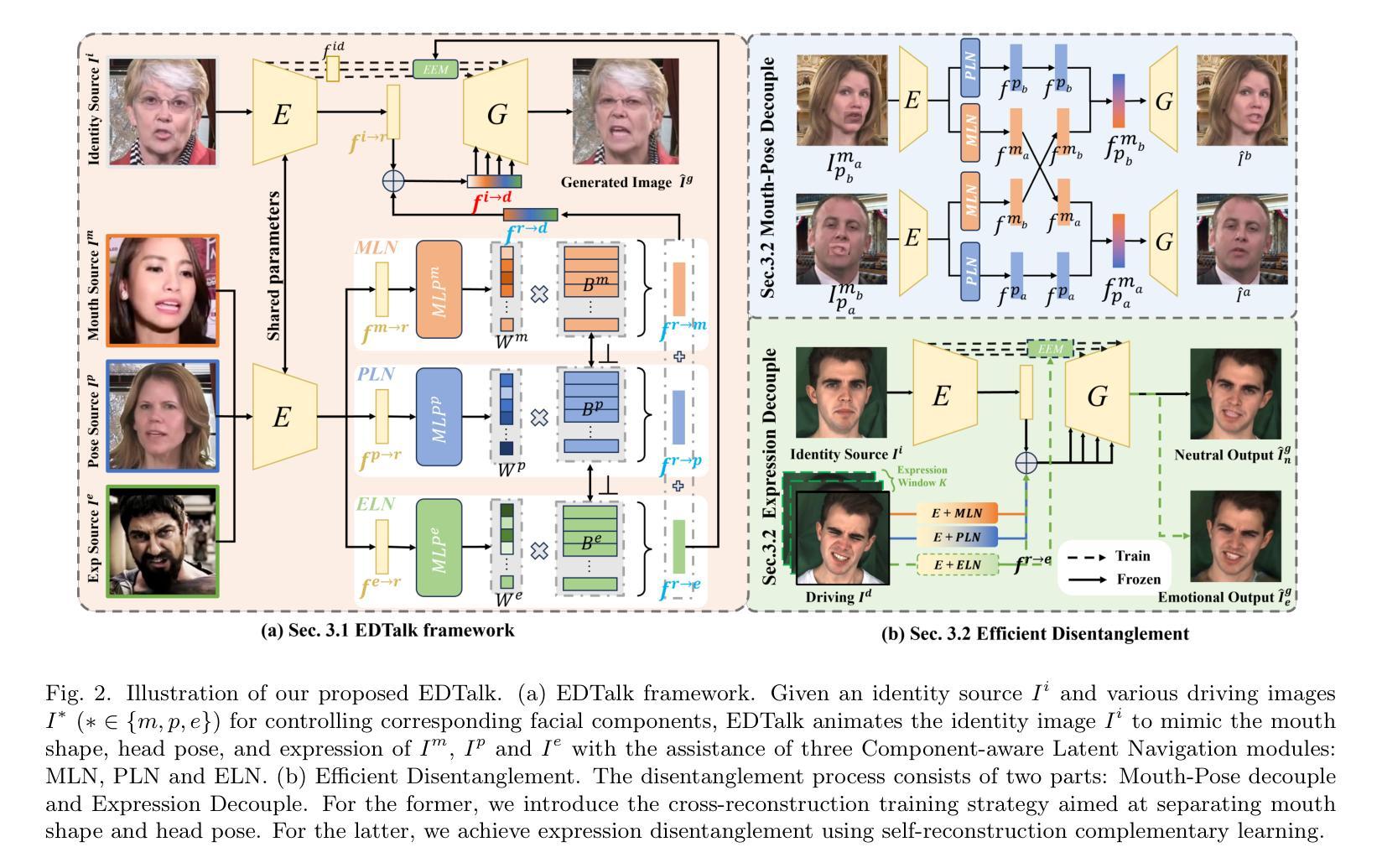
(1)高效解耦策略: 提出解耦策略,包括嘴型-头部姿态解耦和表情解耦,将整体面部动态分解为嘴型、头部姿态和表情空间。
(2)嘴型-头部姿态解耦: 采用交叉重建技术,合成嘴型交换后的图像,并通过重构损失、感知损失和对抗损失监督嘴型-头部姿态解耦模块。
(3)表情解耦: 引入表情感知潜在导航模块和情感增强模块,通过自重建补充学习训练表情解耦模块。
(4)音频到动作: 设计三个模块从音频预测头部姿态、嘴型和表情的权重,通过特征损失、重构损失和同步损失训练音频编码器和权重预测层。
- 结论: (1): 本文提出 EDTalk,一种新颖的系统,旨在将面部组件高效解耦到潜在空间中,从而实现说话人头部合成的精细控制。核心思想是使用存储在专用库中的正交基来表示每个空间。我们提出了一种高效的训练策略,该策略可以自动将空间信息分配给每个空间,从而消除了对外部或先验结构的需要。通过集成这些空间,我们通过轻量级的 Audio-to-Motion 模块实现了音频驱动的说话人头部生成。实验表明,我们的方法在实现对各种面部动作的解耦和精细控制方面具有优越性。我们在附录中提供了有关局限性和伦理考虑的更多讨论。 (2): 创新点:提出了一种高效的解耦策略,该策略包括嘴型-头部姿态解耦和表情解耦;提出了一种基于交叉重建技术的嘴型-头部姿态解耦模块;提出了一种引入表情感知潜在导航模块和情感增强模块的表情解耦模块;设计了一个从音频预测头部姿态、嘴型和表情权重的 Audio-to-Motion 模块。 性能:在说话人头部生成任务上,EDTalk 实现了出色的性能,在视频和音频输入条件下均能实现嘴型、头部姿态和表情的独立控制。实验结果验证了 EDTalk 的有效性,证明了其在说话人头部生成中的应用潜力。 工作量:本文的工作量较大,涉及到解耦策略、嘴型-头部姿态解耦模块、表情解耦模块和 Audio-to-Motion 模块的设计和实现。实验部分也比较复杂,包括定量和定性评估。
点此查看论文截图


FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio
Authors:Chao Xu, Yang Liu, Jiazheng Xing, Weida Wang, Mingze Sun, Jun Dan, Tianxin Huang, Siyuan Li, Zhi-Qi Cheng, Ying Tai, Baigui Sun
In this paper, we abstract the process of people hearing speech, extracting meaningful cues, and creating various dynamically audio-consistent talking faces, termed Listening and Imagining, into the task of high-fidelity diverse talking faces generation from a single audio. Specifically, it involves two critical challenges: one is to effectively decouple identity, content, and emotion from entangled audio, and the other is to maintain intra-video diversity and inter-video consistency. To tackle the issues, we first dig out the intricate relationships among facial factors and simplify the decoupling process, tailoring a Progressive Audio Disentanglement for accurate facial geometry and semantics learning, where each stage incorporates a customized training module responsible for a specific factor. Secondly, to achieve visually diverse and audio-synchronized animation solely from input audio within a single model, we introduce the Controllable Coherent Frame generation, which involves the flexible integration of three trainable adapters with frozen Latent Diffusion Models (LDMs) to focus on maintaining facial geometry and semantics, as well as texture and temporal coherence between frames. In this way, we inherit high-quality diverse generation from LDMs while significantly improving their controllability at a low training cost. Extensive experiments demonstrate the flexibility and effectiveness of our method in handling this paradigm. The codes will be released at https://github.com/modelscope/facechain.
Summary
利用单一音频生成多样化的高保真动态人脸,它解决了两大难题:有效分离音频中纠缠的身份、内容和情感,以及保持视频内部多样性和视频间一致性。
Key Takeaways
- 提出“倾听和想象”任务,将人类听到语音、提取有意义特征并创造动态一致的人脸表情过程抽象化。
- 创新性地将进步式音频分离应用于人脸几何和语义学习,以准确分离身份、内容和情感。
- 引入可控连贯帧生成,使用三个可训练适配器和冻结的潜在扩散模型,专注于保持人脸几何、语义、纹理和帧间时间连贯性。
- 继承潜在扩散模型的高质量生成能力,同时通过低训练成本显著提高可控性。
- 实验结果证明了该方法在处理此范例方面的灵活性和有效性。
- 代码将在 https://github.com/modelscope/facechain 上发布。
- 题目:FaceChain-ImagineID:自由生成高保真多样化说话人脸
- 作者:Chao Xu, Yang Liu, Jiazheng Xing, Weida Wang, Mingze Sun, Jun Dan, Tianxin Huang, Siyuan Li, Zhi-Qi Cheng, Ying Tai, Baigui Sun
- 第一作者单位:阿里巴巴集团
- 关键词:人脸生成、音频解耦、可控生成、一致性
- 论文链接:https://arxiv.org/abs/2403.01901
- 摘要: (1)研究背景: 随着人脸生成技术的不断发展,人们对隐私保护和虚拟形象个性化的需求日益增长。传统方法要么使用真实人脸图像,存在隐私泄露风险,要么生成的虚拟形象与真实音频不一致。
(2)过去方法及问题: 过去方法主要通过音频特征提取和图像生成相结合的方式进行人脸生成,但存在以下问题: - 无法有效解耦音频中的身份、内容和情绪信息。 - 难以在单一模型中实现视觉多样性和音频同步动画。
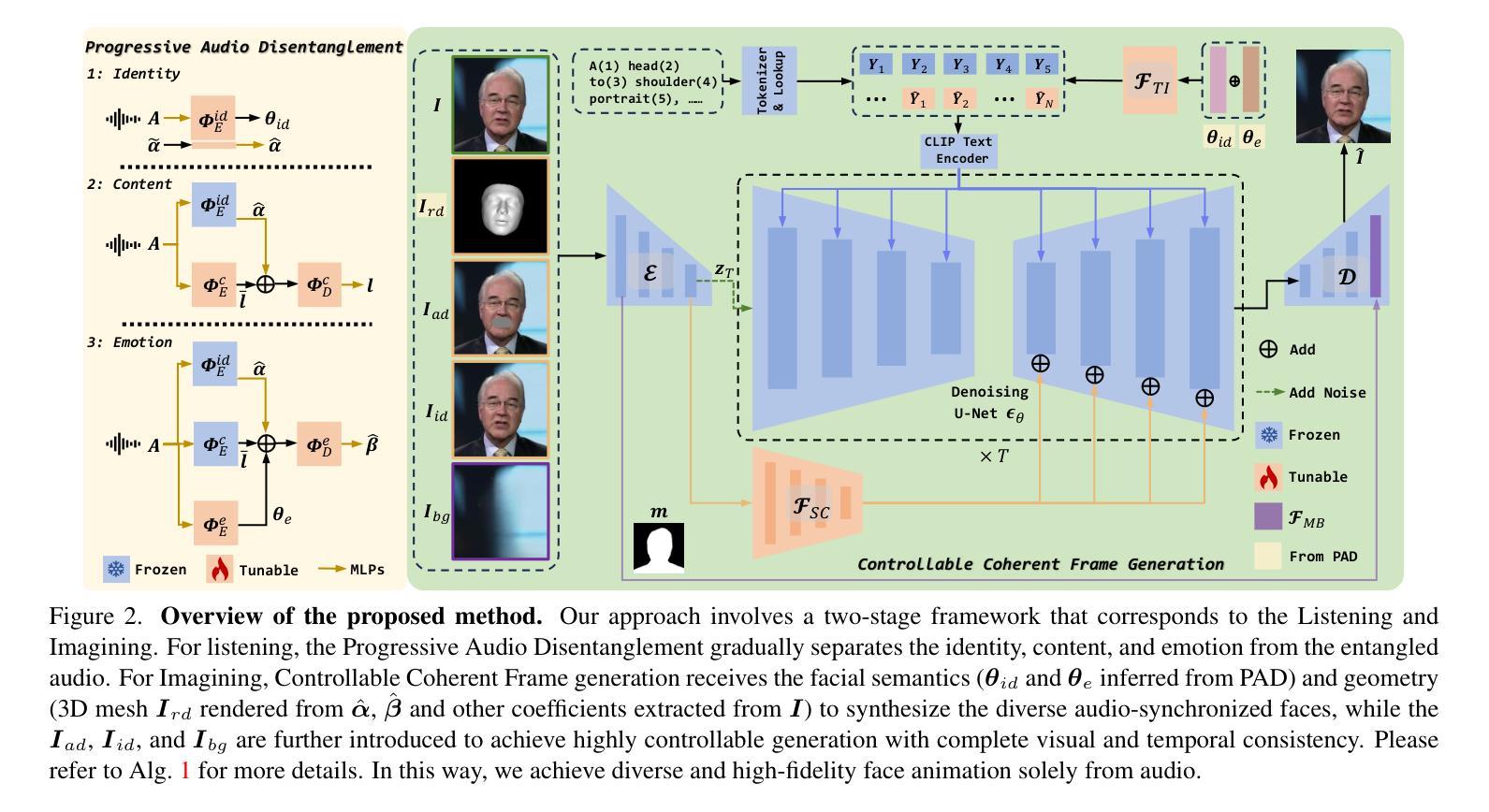
(3)研究方法: 本文提出了“聆听与想象”范式,将人脸生成过程抽象为从音频中提取有意义信息并生成动态音频一致说话人脸的任务。具体来说,方法包含以下两个关键挑战: - 音频解耦:有效地从纠缠的音频中解耦身份、内容和情绪信息。 - 一致性控制:在单一模型中保持视频内多样性和视频间一致性。 为了解决这些挑战,本文提出了渐进式音频解耦和可控一致帧生成方法: - 渐进式音频解耦:通过定制的训练模块,逐级学习身份、语义和情绪信息。 - 可控一致帧生成:通过可训练适配器与冻结的潜在扩散模型集成,保持面部几何和语义、纹理和帧间时间一致性。
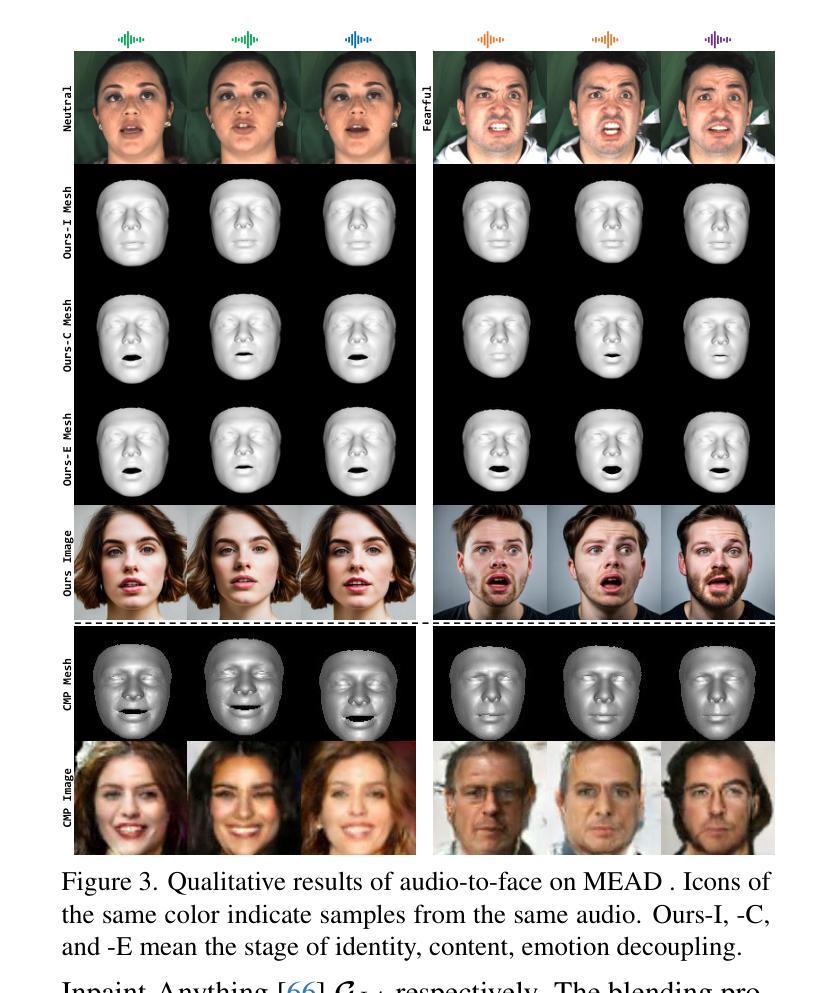
(4)任务和性能: 本文方法在以下任务上取得了较好的性能: - 高保真多样化说话人脸生成:从单一音频生成视觉多样且与音频同步的人脸视频。 - 可控属性编辑:根据个人喜好,自由改变与音频无关的属性,如胡须、发型和瞳孔颜色。 实验结果表明,该方法在处理“聆听与想象”范式时具有较好的灵活性和有效性。
-
方法: (1) 渐进式音频解耦:使用定制的训练模块,逐级学习音频中的身份、语义和情绪信息。 (2) 可控一致帧生成:通过可训练适配器与冻结的潜在扩散模型集成,保持面部几何和语义、纹理和帧间时间一致性。
-
结论: (1):本文提出了一种基于“聆听与想象”范式的说话人脸生成方法,有效解决了音频解耦和一致性控制问题,实现了高保真、多样化、可控的人脸视频生成。该方法为隐私保护、虚拟形象个性化等领域提供了新的解决方案。 (2):创新点:
- 提出“聆听与想象”范式,将人脸生成抽象为从音频中提取信息并生成动态一致人脸的任务。
- 设计渐进式音频解耦模块,逐级学习音频中的身份、语义和情绪信息。
- 提出可控一致帧生成方法,通过可训练适配器与冻结的潜在扩散模型集成,保持视频内多样性和视频间一致性。 性能:
- 在高保真多样化说话人脸生成任务上取得了较好的性能,生成的视频具有视觉多样性,与音频同步。
- 支持可控属性编辑,允许用户根据个人喜好自由改变与音频无关的属性。 工作量:
- 本文方法需要大量的数据和计算资源进行训练。
- 渐进式音频解耦和可控一致帧生成方法的实现较为复杂,需要较高的技术门槛。
点此查看论文截图


 wechat
wechat- alipay







